4
6
14
新手上路
“我们一直在创新” Peter DeSantis说道,“在不需要牺牲安全的情况下,减少我们的成本,同时提高我们的性能,让客户及应用获得更好的体验。”
今天,我们重磅发布Nitro v5!基于ARM架构的Nitro 芯片中的晶体管数量比前一代增加了一倍,提供了更多的计算性能,同时带来50%的 DRAM 内容性能提升,2倍的PCle 带宽提升。 相比于前一代产品,Nitro 将显著改善延迟30%,同时每瓦性能提高40%,PPS 提高60%。
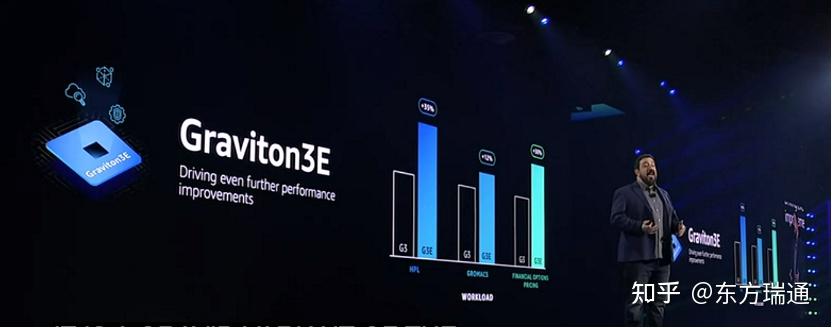
新版本的基于 Arm 的定制 Graviton3E系列芯片,专为支持高性能计算工作负载而设计。新的Graviton3E 芯片,相比现有 Graviton 系列,有着更高的性能提升,对依赖矢量指令的工作负载的性能提高35%。
基于 Graviton3E 芯片,我们推出了面向高性能计算的 HPC7g ,适用于天气预报、生命科学、工程计算等高性能计算场景。这种新的实例类型有多种大小,最多具有64个 vCPU 和 128GiB 内存,这些实例将在2023年初正式投入商用。
相比于 C7g 实例,C7gn 实例为要求更为严苛的网络密集型工作负载而设计:包含网络虚拟设备(防火墙、虚拟路由器、负载均衡器等)、数据分析和紧密耦合的集群计算作业场景。
在 AI 大模型训练中,从传统的几千参数的 Backprop,到百万级的 Bert,十亿级的 GPT-3、PAML,甚至超大规模的 Switch-C,都在对计算芯片提出新的需求,同时在数据网络层面,计算芯片也正面临着新的挑战。 面向下一代计算、内存加速、并行训练及低网络延迟的 AI 训练需求,我们推出了 Trn1n 实例,针对 Trn1 实例进行了网络优化,增加了1600Gbps EFA 网络功能,使之能够更快地面对超大规模分布式模型训练场景。
我们推出了全新的 ENA Express。ENA Express 以为 Elastic Fabric Adapters 提供支持的 SRD 协议为基础,将流量的 P99 延迟减少了50%,将 P99.9 延迟减少85%(与 TCP 相比),同时还将最大单流带宽从 5Gbps 到增加到了 25Gbps。最重要的是,从此您可以获得更多的每流带宽和更少的可变性。 您可以在新的和现有的 ENA 上启用 ENA Express,并立即利用此性能来处理在同一可用区中运行的 c6gn 实例之间的 TCP 和 UDP 流量。
现在,我们面向 Lambda 的创新仍未止步。Peter 用 Lambda 的冷启动时间优化来说明这一点。 在通常情况下,当某个功能长时间不使用时,Lambda 会关闭虚拟机,尽管有了更快的 Firecracker microVM 等改进,但这仍然需要一段时间。
现在,借助 SnapStart,我们可以通过创建客户 Lambda 函数快照来解决这个问题,只需启动它们而无需经过常规的初始化过程。这项新功能现在可供所有 Lambda 用户使用,通过现有的 Lambda 函数即可启动。目前,这项服务适用于使用 Corretto 运行时的 Java 函数。 启用后,当您首次运行该函数时,它将执行标准初始化。之后,它将创建内存和磁盘状态的加密快照并缓存以供重用。然后,当再次调用该函数时,Lambda 将获取缓存并启动该函数。缓存的快照在闲置14天后将被删除。
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|聆讯新闻网
GMT+8, 2025-4-9 02:35 , Processed in 0.106910 second(s), 22 queries .
Powered by Discuz! X3.4
Copyright © 2001-2021, Tencent Cloud.



 发表于 2022-12-17 20:21:59
发表于 2022-12-17 20:21:59